
[견고한 데이터 엔지니어링] 02장

[견고한 데이터 엔지니어링] 2장. 데이터 엔지니어링 수명 주기
읽은 책: Fundamentals of Data Engineering (Joe Reis, Matt Housley) 목표: 데이터 엔지니어링 수명 주기의 각 단계를 깊이 이해하고, 실제 현장에서 Airbyte·dbt가 어느 위치에 놓이는지 파악하기
0. 이 장이 던지는 질문
1장에서 생애주기를 큰 그림으로 훑었다면, 2장은 각 단계를 해부한다. 단계별로 무엇을 결정해야 하고, 어떤 트레이드오프가 존재하는지 구체적으로 다룬다.
이 장의 핵심 질문:
- 수명 주기 각 단계에서 데이터 엔지니어가 실제로 무엇을 하는가?
- 각 단계에서 “좋은 선택”과 “나쁜 선택”의 기준은 무엇인가?
- 수명 주기를 관통하는 언디커런트(Undercurrents)는 어떻게 작동하는가?
- 현대 데이터 스택(Airbyte + dbt)은 이 프레임워크의 어디에 위치하는가?
1. 데이터 엔지니어링 수명 주기 전체 구조
[소스 시스템]
|
v
생성(Generation) → 수집(Ingestion) → 저장(Storage) → 변환(Transformation) → 서빙(Serving)
|
분석가 / 데이터 과학자 / 애플리케이션
언뜻 선형처럼 보이지만, 실제로는 순환적이다. 서빙 단계에서 발생한 요구사항이 수집 방식에 영향을 주고, 저장 전략이 변환 비용을 결정한다.
개인 메모: 파이프라인 설계를 “소스부터 시작”하면 방향을 잃기 쉽다. 서빙 단계에서 역방향으로 설계하는 게 더 실용적이다. “최종 사용자가 무엇을 필요로 하는가”가 출발점이어야 한다.
2. 소스 시스템(Source Systems)
2.1 소스 시스템이란
데이터가 처음 만들어지는 곳. 데이터 엔지니어가 직접 제어하지 않는 영역이다.
- 애플리케이션 데이터베이스(OLTP)
- 이벤트/로그 스트림
- IoT 디바이스, 센서
- 서드파티 SaaS(CRM, ERP, 광고 플랫폼 등)
- 외부 파일(CSV, JSON, Excel 등)
2.2 소스 시스템을 이해해야 하는 이유
소스 시스템의 특성은 수집·저장·변환 방식을 결정한다.
| 특성 | 영향 |
|---|---|
| 변경 빈도(Update Frequency) | 배치 주기 또는 스트리밍 필요 여부 결정 |
| 데이터 볼륨 | 저장 비용·수집 방식 결정 |
| 스키마 안정성 | 스키마 변경 감지·대응 전략 필요 여부 |
| 데이터 품질 | 수집 후 품질 검증 로직 설계 수준 |
개인 메모: 소스 시스템 담당자(애플리케이션 개발팀)와의 협업이 중요하다. 스키마가 변경됐는데 아무 공지 없이 파이프라인이 터지는 상황을 예방하려면, 소스 변경에 대한 사전 알림 프로세스가 필수다.
3. 수집(Ingestion)
3.1 수집이란
소스 시스템의 데이터를 데이터 파이프라인으로 가져오는 단계. 데이터가 “외부”에서 “우리 관리 영역”으로 넘어오는 경계선이다.
3.2 배치(Batch) vs 스트리밍(Streaming)
가장 중요한 설계 결정 중 하나다.
| 구분 | 배치 수집 | 스트리밍 수집 |
|---|---|---|
| 방식 | 정해진 주기(시간, 일 단위)로 대량 처리 | 이벤트 발생 즉시 처리 |
| 지연(Latency) | 높음(분~시간 단위) | 낮음(초 단위 이하) |
| 복잡도 | 낮음 | 높음 |
| 비용 | 상대적으로 낮음 | 상대적으로 높음 |
| 대표 도구 | Airbyte, Fivetran, COPY INTO | Kafka, Kinesis, Flink |
핵심 트레이드오프: 스트리밍이 항상 더 좋은 것이 아니다. 대부분의 분석 워크로드는 배치로도 충분하다. 복잡성과 비용을 감수할 만큼의 실시간 요구가 있는지 먼저 검토해야 한다.
3.3 CDC(Change Data Capture)
소스 DB의 변경 사항(INSERT/UPDATE/DELETE)만 증분으로 가져오는 기법. 전체 테이블을 매번 복사하는 풀 스냅샷 방식의 대안이다.
- 장점: 소스 시스템 부하 감소, 수집 데이터 볼륨 감소
- 단점: 소스 DB 설정 필요, 구현 복잡도 증가
3.4 현장 연결: Airbyte
Airbyte는 수집(Ingestion) 단계를 담당하는 오픈소스 EL(Extract-Load) 도구다.
소스 시스템 → [Airbyte: Extract + Load] → 데이터 웨어하우스/레이크
- Connector 생태계: 300개 이상의 사전 구축 커넥터(PostgreSQL, MySQL, Salesforce, Google Analytics 등)
- 동기화 모드: Full Refresh(전체 재적재), Incremental Append(증분 추가), Incremental Dedup(증분 + 중복 제거)
- CDC 지원: 주요 RDBMS에 대해 CDC 기반 수집 가능
- 스키마 변경 감지: 소스 스키마가 바뀌면 알림을 보내거나 자동으로 대응하도록 설정 가능
개인 메모: Airbyte는 “수집을 직접 구현하지 않아도 된다”는 점이 핵심 가치다. 어떤 동기화 모드를 선택하느냐에 따라 다운스트림 변환 로직이 달라지므로, 수집 방식과 변환 전략을 처음부터 함께 설계해야 한다.
4. 저장(Storage)
4.1 저장의 핵심 질문
단순히 “어디에 저장할까”가 아니라:
- 어떤 접근 패턴이 예상되는가? (분석 쿼리 vs 포인트 조회)
- 데이터를 얼마나 자주 읽고 쓰는가?
- 비용 최적화와 성능 사이의 균형은?
- 데이터 보존 기간과 아카이빙 정책은?
4.2 저장 시스템의 종류
| 저장 시스템 | 특성 | 대표 서비스 |
|---|---|---|
| 오브젝트 스토리지 | 저비용, 대용량, 분석 워크로드에 최적 | S3, GCS, Azure Blob |
| 데이터 웨어하우스 | 구조화된 분석 쿼리에 최적, 관리형 | BigQuery, Snowflake, Redshift |
| 데이터 레이크 | 원시 데이터 보존, 스키마 유연성 | S3 + Iceberg/Delta, Databricks |
| RDBMS(OLTP) | 트랜잭션 처리, 포인트 조회 | PostgreSQL, MySQL |
| 스트리밍 저장소 | 이벤트 스트림 보존 | Kafka, Kinesis |
4.3 데이터 레이크하우스(Data Lakehouse)
최근 트렌드는 데이터 레이크의 유연성과 데이터 웨어하우스의 관리 기능을 합친 레이크하우스 아키텍처다.
- Apache Iceberg, Delta Lake, Apache Hudi 같은 오픈 테이블 포맷이 핵심
- ACID 트랜잭션, 스키마 진화, 타임 트래블(Time Travel) 기능 제공
개인 메모: 인턴십 초기에는 관리형 데이터 웨어하우스(BigQuery, Snowflake 등)부터 시작하는 게 현실적이다. 레이크하우스는 데이터 규모와 팀 역량이 갖춰진 다음에 고려해도 늦지 않다.
5. 변환(Transformation)
5.1 변환이란
원시 데이터를 분석·ML에 적합한 형태로 가공하는 단계. 수명 주기에서 데이터 엔지니어가 가장 많은 시간을 투자하는 단계이기도 하다.
5.2 변환의 주요 작업
- 정제(Cleansing): 결측값 처리, 형식 표준화, 중복 제거
- 집계(Aggregation): 일별/월별 합계, 평균 등 요약 지표 생성
- 조인(Join): 여러 소스 테이블 결합
- 비즈니스 로직 적용: 매출 계산 방식, 사용자 세그멘테이션 규칙 등
- 데이터 모델링: 분석 목적에 맞는 테이블 구조 설계(Star Schema, OBT 등)
5.3 ELT vs ETL
| 구분 | ETL (Extract-Transform-Load) | ELT (Extract-Load-Transform) |
|---|---|---|
| 변환 위치 | 데이터 웨어하우스 외부 | 데이터 웨어하우스 내부 |
| 도구 | 전통적 ETL 툴(Informatica 등) | dbt, SQL |
| 유연성 | 낮음 | 높음 |
| 현대 트렌드 | 감소 | 주류 |
클라우드 데이터 웨어하우스의 컴퓨팅 파워가 저렴해지면서 ELT가 현재 주류다. 소스 데이터를 먼저 그대로 적재하고, 웨어하우스 안에서 SQL로 변환하는 패턴이다.
5.4 현장 연결: dbt
dbt(data build tool)는 변환(Transformation) 단계를 담당하는 오픈소스 도구다.
데이터 웨어하우스(Raw) → [dbt: Transform] → 데이터 웨어하우스(Mart/Analytics)
dbt의 핵심 가치:
- SQL로 변환 로직을 작성하면, dbt가 실행 순서(DAG)와 의존성을 자동으로 관리
- 테스트: not_null, unique, accepted_values 등 데이터 품질 테스트를 선언적으로 정의
- 문서화: 모델별 description, lineage 그래프를 자동 생성
- 버전 관리: 모든 변환 로직이 SQL 파일이므로 Git으로 관리 가능
dbt 프로젝트 구조 예시:
models/
staging/ # 소스 데이터를 1:1로 정제 (Airbyte가 적재한 raw 테이블 참조)
stg_orders.sql
stg_customers.sql
intermediate/ # 비즈니스 로직이 들어가는 중간 단계
int_orders_joined.sql
marts/ # 분석가·대시보드가 직접 사용하는 최종 테이블
fct_orders.sql
dim_customers.sql
개인 메모: staging 레이어에서 Airbyte가 적재한 원시 테이블을 참조하는 패턴이 핵심이다. raw 테이블에 직접 쿼리하는 대신 staging 모델을 거치면, 소스 스키마가 바뀌더라도 staging만 수정하면 하위 모델은 영향을 최소화할 수 있다.
6. 서빙(Serving)
6.1 서빙이란
변환된 데이터를 최종 사용자(분석가, 데이터 과학자, 애플리케이션)에게 전달하는 단계. 아무리 잘 만든 파이프라인도 사용자가 실제로 활용하지 않으면 가치가 없다.
6.2 서빙의 유형
| 유형 | 설명 | 도구 예시 |
|---|---|---|
| BI/분석 | 대시보드, 리포트, 임시 쿼리 | Tableau, Looker, Metabase, Superset |
| ML 피처 스토어 | ML 모델 학습·추론용 피처 제공 | Feast, Tecton |
| 역방향 ETL(Reverse ETL) | 분석 결과를 소스 시스템(CRM 등)에 다시 씀 | Census, Hightouch |
| 운영 분석(Operational Analytics) | 실시간 대시보드, 알림 | Apache Druid, ClickHouse |
6.3 데이터 메시(Data Mesh) 관점
서빙 단계에서 중요한 질문은 “누가 이 데이터의 소유자인가”다. 데이터 메시 아키텍처는 도메인별 팀이 데이터 프로덕트를 직접 소유·제공하는 방식으로 이 문제를 해결한다.
개인 메모: 인턴십에서 dbt로 만든 mart 테이블이 분석가나 BI 도구로 연결되는 것이 서빙의 실체다. “mart 테이블이 얼마나 잘 설계됐는가”가 분석팀의 생산성을 직접 결정한다.
7. 언디커런트(Undercurrents): 수명 주기 전체를 관통하는 요소
수명 주기의 각 단계가 “뭘 할 것인가”라면, 언디커런트는 “어떻게 잘 할 것인가”의 기준이다.
7.1 보안(Security)
- 접근 제어: 누가 어떤 데이터에 접근할 수 있는가?
- 암호화: 저장 중(at-rest) 및 전송 중(in-transit) 암호화
- 민감 데이터: PII(개인식별정보) 마스킹, 접근 로그
개인 메모: Airbyte에서 소스 DB 자격증명을 어떻게 관리하는가, dbt에서 웨어하우스 접근 권한을 어떻게 분리하는가가 실무에서 마주치는 보안 이슈다.
7.2 데이터 관리(Data Management)
- 데이터 카탈로그: 어떤 테이블이 있고 무엇을 의미하는가?
- 데이터 계보(Lineage): 이 데이터가 어디서 왔고 어디로 가는가?
- 데이터 품질: 이 데이터가 신뢰할 수 있는가?
개인 메모: dbt의 문서 자동 생성 기능이 데이터 카탈로그와 lineage를 동시에 해결한다. dbt docs generate → dbt docs serve로 간단하게 문서 사이트를 띄울 수 있다.
7.3 DataOps
- 파이프라인 모니터링: 언제 실패했는가? 얼마나 걸렸는가?
- 장애 대응: 실패 시 알림, 재시도, 롤백
- CI/CD: 코드 변경이 파이프라인에 자동으로 반영되는 프로세스
개인 메모: Airbyte는 sync 실패 시 이메일/슬랙 알림 설정이 가능하다. dbt는 dbt test를 CI에 걸어두면 데이터 품질 이슈를 배포 전에 잡을 수 있다.
7.4 데이터 아키텍처(Data Architecture)
전체 시스템이 어떻게 연결되는가에 대한 설계 원칙. 개별 도구 선택보다 도구들이 어떻게 조합되는가가 더 중요하다.
7.5 오케스트레이션(Orchestration)
파이프라인 간의 의존성과 실행 순서를 관리하는 것.
- “Airbyte sync가 완료된 후에만 dbt run이 실행돼야 한다”는 의존성을 어떻게 표현하는가?
- 대표 도구: Apache Airflow, Dagster, Prefect, dbt Cloud의 스케줄러
개인 메모: Airbyte + dbt를 쓸 때 가장 자주 만나는 질문이 바로 오케스트레이션이다. 단순한 구성에서는 Airbyte 동기화 후 dbt Cloud 트리거를 연결하는 방식으로 시작하고, 복잡해지면 Airflow나 Dagster로 전체 파이프라인을 통합 관리하는 것이 일반적이다.
7.6 소프트웨어 엔지니어링(Software Engineering)
- 코드 품질: 테스트 가능성, 재사용성, 가독성
- 버전 관리: Git 기반 코드 관리
- 코드 리뷰: 변환 로직의 정확성을 동료가 검증
개인 메모: dbt 프로젝트는 완전히 Git으로 관리되는 SQL 코드베이스다. Pull Request 리뷰를 통해 변환 로직의 정확성을 검증하는 습관이 중요하다.
8. 현대 데이터 스택: Airbyte + dbt 전체 그림
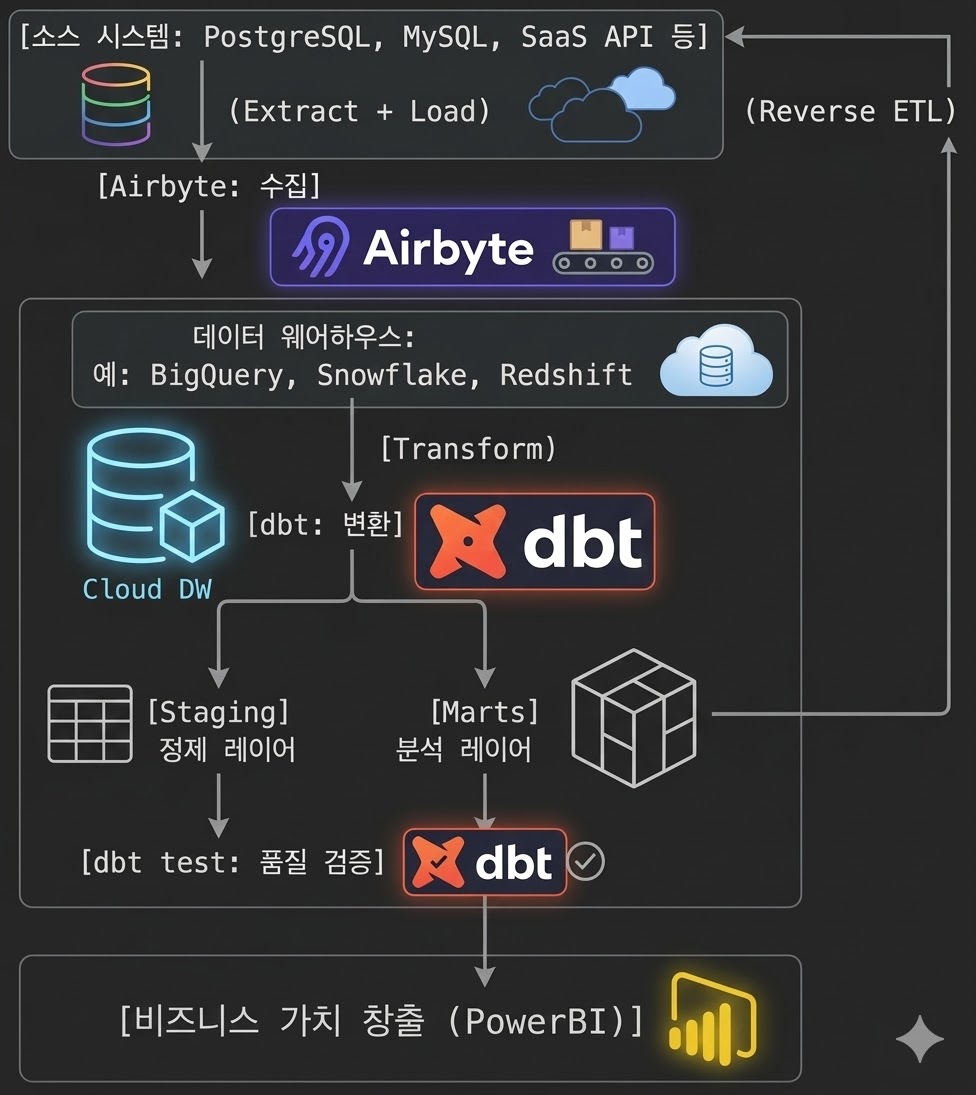
이 구조는 “견고한 데이터 엔지니어링”의 수명 주기를 현대 도구로 구현한 표준 패턴이다.
- Airbyte = 수집(Ingestion) 단계를 담당
- 데이터 웨어하우스 = 저장(Storage) 단계를 담당
- dbt = 변환(Transformation) 단계를 담당
- BI 도구 = 서빙(Serving) 단계를 담당
9. 이 장의 결론
- 수명 주기는 생성 → 수집 → 저장 → 변환 → 서빙의 흐름이지만, 서빙 요구사항에서 역방향으로 설계하는 게 실용적이다.
- 배치 vs 스트리밍 선택은 비즈니스 요구사항의 실시간성에 따라 결정해야 한다. 스트리밍이 항상 정답이 아니다.
- ELT 패턴이 현대 데이터 스택의 주류다. Airbyte로 적재하고, dbt로 변환하는 흐름이 그 구현체다.
- 언디커런트(보안, DataOps, 오케스트레이션 등)를 처음부터 설계에 포함해야 한다. 나중에 붙이면 훨씬 비싸진다.
- dbt는 변환 로직을 코드로 관리하게 해주고, lineage와 테스트를 내장한다. 단순한 SQL 실행기가 아니다.
10. 내가 적용해볼 체크리스트
- Airbyte에서 소스를 연결할 때 동기화 모드(Full Refresh vs Incremental)를 의도적으로 선택하고 있는가?
- dbt staging 모델이 raw 테이블과 1:1 대응되도록 구조화되어 있는가?
- dbt 모델에 not_null, unique 등 기본 품질 테스트가 붙어 있는가?
- Airbyte sync → dbt run 의존성이 오케스트레이터로 관리되고 있는가, 아니면 수동으로 실행하고 있는가?
- dbt docs를 생성하면 lineage 그래프에서 데이터 흐름이 한눈에 보이는가?
- 소스 스키마가 변경됐을 때 파이프라인이 어떻게 반응하는지 테스트해봤는가?
11. 한 줄 요약(5줄)
- 데이터 엔지니어링 수명 주기는 수집·저장·변환·서빙의 단계로 구성되며, 서빙 요구사항에서 역방향으로 설계하는 것이 실용적이다.
- 배치와 스트리밍 중 선택은 비용·복잡도·실시간성 요구를 함께 고려해야 한다.
- ELT 패턴이 현대 주류이며, Airbyte(수집) + dbt(변환) 조합이 그 대표적인 구현 방식이다.
- 언디커런트(보안, DataOps, 오케스트레이션 등)는 생애주기 전체에 걸쳐 처음부터 설계에 포함해야 한다.
- dbt는 SQL 변환 로직을 코드로 관리하면서 테스트·문서화·lineage를 내장한 현대 변환 도구의 표준이다.
Leave a comment